How to Scale AI in Business: Leverage Large Language Models and Instana for Enhanced Enterprise Monitoring
In the swiftly evolving landscape of enterprise AI, Large Language Models (LLMs) have become pivotal in driving innovation, efficiency, and competitive edge. As businesses scale their AI operations, the need for robust monitoring tools becomes crucial. IBM Instana, an application performance management (APM) product, emerges as a key player in this domain, offering precise, real-time monitoring capabilities that are indispensable for managing complex AI-driven environments. This blog explores how enterprises can integrate LLMs with Instana to optimize both performance and reliability.
LLM Deployment Patterns
Large Language Models (LLMs) like OpenAI’s GPT series can be deployed and utilized in customer environments in various ways, depending on the specific needs and capabilities of the organization, there are mainly four different patterns including cloud-based deployment, on-premises deployment, hybrid deployment and edge deployment. Here’s an overview of those four different patterns and use cases.
Cloud-Based Deployment
Cloud-based deployment of Large Language Models (LLMs) like GPT offers a wide range of use cases across different industries, due to its scalability, ease of integration, and constant updates. Here are more detailed use cases for utilizing LLMs in a cloud-based setup:
Automated Customer Support
LLMs can automate responses to customer queries on websites, in mobile apps, or via social media platforms. By understanding and processing natural language, these models can provide quick, accurate answers to common questions, reducing the workload on human agents and improving customer satisfaction.
Personalized Content Creation
Cloud-based LLMs can help in generating personalized content for users based on their previous interactions, preferences, or browsing history. This can be particularly useful in applications like dynamic email marketing campaigns, personalized article recommendations, or even creating customized fitness plans in health apps.
Language Translation Services
Companies operating in multiple countries can use LLMs to provide real-time translation services, enhancing communication across different language speakers. This capability can be integrated into chat applications, customer support tools, or any platform requiring multilingual interactions.
Sentiment Analysis
LLMs can analyze text from social media, reviews, or customer feedback to determine the sentiment (positive, negative, neutral) behind the text. This information can help businesses gauge public opinion, monitor brand reputation, and improve product offerings based on customer feedback.
Educational Tools
Educational platforms can use LLMs to provide tutoring or assistance in learning new materials. For example, an LLM can generate practice questions, explain complex topics in simpler terms, or offer real-time help during learning sessions.
Financial Analysis and Reporting
In finance, LLMs can analyze market trends, generate reports, and offer insights based on historical data. They can also assist in drafting personalized financial advice based on user-specific data, helping financial advisors to serve their clients more effectively.
On-Premises Deployment
On-premises deployment of Large Language Models (LLMs) offers specific advantages, particularly in terms of data security, compliance with regulations, and integration with sensitive systems. Here are some use cases where on-premises deployment might be particularly beneficial:
Healthcare Data Analysis
Due to the sensitive nature of medical data and strict compliance requirements like HIPAA in the U.S., healthcare providers may prefer on-premises deployment. LLMs can assist in analyzing patient data, generating insights for personalized treatment plans, and even helping with diagnostic processes by reviewing symptoms and medical histories.
Financial Services
Banks and financial institutions often deal with sensitive financial data and are subject to stringent regulatory requirements. On-premises LLMs can help with risk assessment, fraud detection, customer service, and compliance checks without exposing data externally.
Government and Public Sector
Governments can use on-premises LLMs to handle confidential data securely. Applications include drafting and managing public communications, analyzing policy feedback, automating bureaucratic processes, and maintaining records securely.
Enterprise Data Analysis
Large enterprises can use LLMs on-premises to analyze internal data, such as sales, HR, and operational data, without the risk of exposing it to external cloud providers. This can help in generating business insights, forecasting trends, and enhancing decision-making processes.
Legal Document Processing
For legal firms handling sensitive and confidential information, on-premises LLMs can automate tasks such as document review, contract analysis, and case research. This not only ensures data privacy but also improves efficiency in handling large volumes of documents.
Research and Development
Organizations that conduct proprietary research, such as pharmaceutical companies, can use on-premises LLMs to analyze research data, write research papers, and develop new product ideas without the risk of intellectual property theft.
Telecommunications
Telecom companies can deploy LLMs on-premises to manage and analyze vast amounts of data generated from networks and users. Applications include customer service automation, network optimization, and fraud detection.
Hybrid Deployment
Hybrid deployment of Large Language Models (LLMs) leverages both cloud and on-premises resources, providing a flexible and efficient solution that balances security, privacy, and computational power. This approach is particularly useful in scenarios where sensitive data handling is necessary, but the scalability of cloud resources is also needed. Here are several use cases where hybrid deployment can be particularly effective:
Sensitive Data Analysis
Organizations that handle sensitive data, like those in healthcare or finance, can process and store this data on-premises to comply with legal and privacy standards while using cloud-based resources for less sensitive computational tasks, such as generating general insights or reports.
Disaster Recovery
Hybrid deployments can ensure business continuity and data recovery. Critical data can be backed up on-premises, while additional copies are stored in the cloud, providing redundancy and protecting against data loss in case of hardware failures or other disasters.
Scalable Customer Support
A hybrid approach allows for the secure handling of customer data on-premises while utilizing cloud-based LLMs for handling peak loads during high-demand periods. This ensures customer inquiries are managed quickly without compromising the security of sensitive information.
Research and Development
Companies involved in research can use on-premises systems to handle proprietary or sensitive experiments and data, while leveraging cloud resources for high-performance computing tasks, such as simulations or data analytics that are less sensitive.
Regulatory Compliance and Data Sovereignty
For organizations operating in multiple jurisdictions, hybrid deployment allows for local processing and storage of data to meet specific regional regulations and data sovereignty requirements, while still benefiting from the cloud’s scalability for global operations.
Hybrid IoT Systems
In Internet of Things (IoT) applications, sensitive data can be processed locally on devices or on-premises systems to reduce latency and enhance security, while aggregated, non-sensitive data can be analyzed in the cloud to benefit from advanced analytics and AI capabilities.
Multi-tier Data Management
Data can be tiered where more sensitive or frequently accessed data is kept and handled on-premises, and less sensitive, archival data is stored in the cloud, optimizing costs and performance.
Edge Deployment
Edge deployment of Large Language Models (LLMs) involves placing the computational resources closer to where data is generated or where actions need to be taken, reducing latency and bandwidth use, and enhancing real-time data processing capabilities. Here are some use cases where edge deployment can be particularly beneficial:
Autonomous Vehicles
In autonomous driving, vehicles need to process massive amounts of data from sensors in real-time to make immediate decisions. Deploying LLMs at the edge, directly in vehicles, allows for faster processing without the latency that would come with sending data to a central server or cloud.
Manufacturing Automation
Manufacturing facilities can use edge-deployed LLMs to monitor equipment and production lines in real-time. This allows for immediate adjustments and anomaly detection to prevent equipment failures or production defects, enhancing operational efficiency and reducing downtime.
Smart Cities
In smart city applications, edge computing can manage everything from traffic systems to public safety monitoring. LLMs can process data locally, such as from cameras and sensors, to manage traffic flows, monitor crowds, and even detect criminal activities in real-time.
Healthcare Monitoring
Edge computing can be used in healthcare settings for real-time patient monitoring and diagnostics. For example, wearable devices can process health data on the device itself to provide immediate alerts and health insights without the need to constantly connect to a cloud server.
Retail and Customer Service
In retail, edge-deployed LLMs can enhance customer service by providing personalized assistance through smart kiosks or mobile apps that interact with customers in real-time, offering product recommendations and information without delays.
Energy Management
For energy utilities, edge computing can optimize the operation of grids by analyzing consumption data in real-time at local substations. This helps in dynamically balancing loads and integrating renewable energy sources effectively.
Augmented Reality (AR) and Virtual Reality (VR)
AR and VR applications require fast processing to deliver immersive experiences. Edge computing allows LLMs to process user interactions and environment data locally, reducing lag and improving the responsiveness of AR/VR systems.
Supply Chain Logistics
In logistics, edge computing can track goods and manage inventory in real-time throughout the supply chain. LLMs can predict and manage stock levels at local depots, optimizing supply chain operations and reducing delays.
LLM Observability Focus for different Patterns
Cloud-Based Deployment
- Scalability Monitoring: Observability in cloud deployments should focus on scalability, including the ability to monitor dynamic scaling of resources to handle varying loads.
- Performance Metrics: Key metrics such as response times, throughput, and error rates need to be tracked continuously to gauge the performance of the LLM.
- Cost Management: Observing resource usage to manage costs effectively is crucial, especially in a cloud environment where costs are directly tied to resource usage.
On-Premises Deployment
- Infrastructure Health: Monitoring the health of physical servers, storage, and networking equipment is critical.
- Security Observability: Since on-premises deployments often handle sensitive data, observing security metrics and logs becomes a priority.
- Compliance Auditing: Continuous observability must also focus on compliance with internal and external standards and regulations.
Hybrid Deployment
- Cross-Environment Integration: Observing how components interact across cloud and on-premises environments is essential.
- Latency and Performance: Special attention should be given to network latency and performance bottlenecks that may occur due to the distributed nature of hybrid deployments.
- Data Flow and Security: Observing data transfer between cloud and on-prem environments to ensure data integrity and security.
Edge Deployment
- Device Management: Monitoring the health and performance of edge devices is key due to their critical role in data processing.
- Network Stability: Observability must include network performance, especially given that edge devices often operate over less stable networks.
- Local Data Processing: Understanding the performance of local data processing tasks is important for maintaining overall system efficiency.
LLM Observability with Instana
Full AI Stack Observability
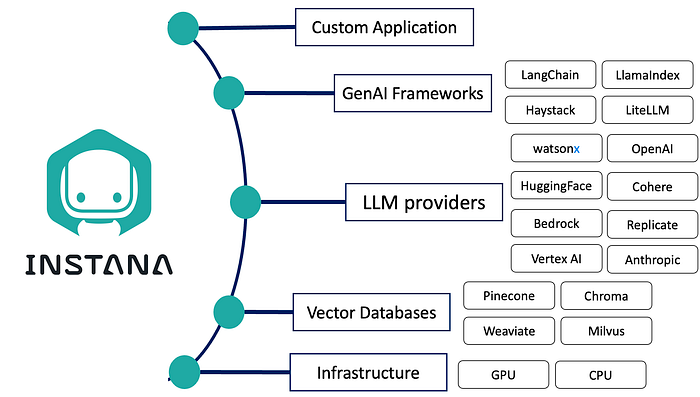
Instana offers comprehensive monitoring capabilities that can be adapted to the needs of LLM deployment for the full AI Stack. Here’s how you can use Instana to monitor the different deployment patterns:
Infrastructure Observability
This layer serves as the foundational platform for AI development and implementation, including GPUs and CPUs for training and deploying AI models. Additionally, cloud computing services like AWS, Azure, and GCP offer scalable environments for rolling out AI applications.
For some cases if you want to run or build your own models, you may want some GPU resources. For GPU, we need to monitor the metrics like GPU utilization, memory utilization, temperate and power consumption etc.
Data storage and vector databases
This layer is essential for AI applications, these data storage solutions handle the retention and retrieval of vast datasets. Vector databases are tailor-made for high-dimensional data management, a common requirement in AI applications.
If you want to build some RAG application with your local private data, you may want to use vector db to persist your own data, like you can use pinecone, chroma, Milvius, Weaviate etc.
Model Layer
This layer contains advanced AI models that drive predictive analytics and output generation. Notable models in content generation include IBM Granite, GPT-4, GPT-3, Anthropic, Cohere, LLama 2 etc.
For models, the major metrics that the customer will care includes token usage, model cost, model latency, model accuracy etc.
Orchestration Framework
Tools such as LangChain, LiteLLM facilitate the seamless integration of various AI application elements, encompassing data manipulation, model invocation, and post processing.
If you want to build some complex AI applications, you may want to leverage some model orchestration platforms, like langchain, llamaindex etc to build your AI application which may contain like agents, models, vectordb etc.
Customer Application
This user-centric layer comprises applications that leverage AI models. Instana supports a wide range of automatic discovery and instrumentation capabilities enabling end-to-end tracing and observability of business and user workflows.
Instana AI Observability
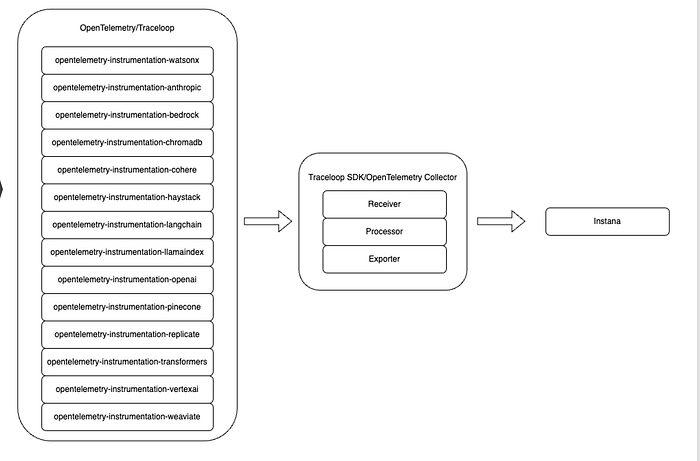
With Instana, OpenTelemetry is the foundation for AI Observability, we are using a open source project named as openllmetry which provides bunch of opentelemetry instrumentation code to emit metrics and tracing for different models, vectordbs, model orchestration platforms etc.
The major component we used for metrics/tracing collection is opentelemetry collector, it is kind of pipeline and it mainly have three core components, including receiver, processor and exporter.
- Receivers are the entry points for data into the OpenTelemetry Collector. They are responsible for accepting and ingesting telemetry data from various sources. Receivers can support different types of telemetry data, including metrics, logs, and traces. Some receivers collect data over the network, listening for data sent over protocols such as HTTP, gRPC, or UDP, while others collect data from the host machine, such as system metrics or logs.
- Processors manipulate, transform, or enrich the data as it flows through the Collector. They can perform a wide range of operations, from simple tasks like batch processing and filtering to more complex manipulations like transforming data formats and adding additional context to telemetry data.
- Exporters are responsible for sending processed telemetry data to one or more destinations. These destinations can be analysis tools, observability platforms, storage systems, or any other service capable of receiving and processing telemetry data.
With Openllmetry Instrumentation packages and traceloop sdk which is kind of OpenTelemetry Collector, Instana will be able to collect the full AI stack metrics/tracing and shwo them on instana dashboard.
Instana Events/Alerts/Automation
To enhance system performance and reliability, especially in large scale deployments like those of large language models (LLMs), it is essential to have a robust observability framework integrated with automated event and alert management. This combination allows teams to monitor system health in real-time, respond to incidents promptly, and even preemptively address potential issues before they affect performance or user experience.
Events in a system are significant occurrences that might indicate changes, anomalies, or emerging issues. Alerts are automated notifications triggered by these events based on predefined rules or thresholds. Effective management involves:
- Event Detection: Automated systems detect and log events in real-time, categorizing them based on severity and impact.
- Alert Configuration: Configuring alerts involves defining which events should trigger notifications and setting the thresholds that must be breached to initiate an alert.
- Alert Prioritization: Not all alerts are of equal importance. Effective systems categorize alerts by their potential impact on the system, focusing human attention where it is most needed.
Instana can enable customer config some events/alerts based on metrics/tracing from LLM Observability, thus some events/alerts will be triggered if there are any issues detected for LLMs, like we can define a alert based on the metrics of token cost, if the cost exceeds some values, an alert will be generated.
The Instana automation framework supports automating actions to diagnose and remediate events. By using the action catalog, we can create new actions or integrate with existing automation through a script, webhook, or other third-party automation providers. We can associate actions with various Instana events and run the actions by using an action sensor on the Instana host agent. For some LLM events/alerts, we can define some automation ansible playbook to help remediate events/alerts automatically.
